
Peutz voert veelvuldig metingen van bijvoorbeeld geluid en/of trillingen uit. Dit kunnen specifieke metingen over kortere duur zijn, maar ook langdurige monitoringsprojecten. Dit soort langdurige monitoringsprojecten resulteren in grote hoeveelheden data die vaak complex en tijdrovend zijn in analyse. Hierdoor wordt vaak niet de gehele dataset gebruikt. Als hulpmiddel voor de analyse is een machine learning-algoritme ontwikkeld dat een eerste ruwe analyse van de data uitvoert waar de adviseur mee verder kan. Het algoritme zoekt clusters in een N-dimensionale dataset, welke voor de mens moeilijk afzonderlijk te identificeren zijn. Deze clusteringanalyse helpt bij het identificeren van relevante verstoringen, wat vervolgens richting geeft voor een meer gedetailleerdere analyse en interpretatie waar expertkennis van de adviseur voor nodig is. De combinatie van toepassing van machine learning-algoritmes voor het zoeken naar structuur in grote datasets en de interpretatie van deze gegevens door de adviseur leidt tot meer inzicht in de onderliggende vraagstukken.
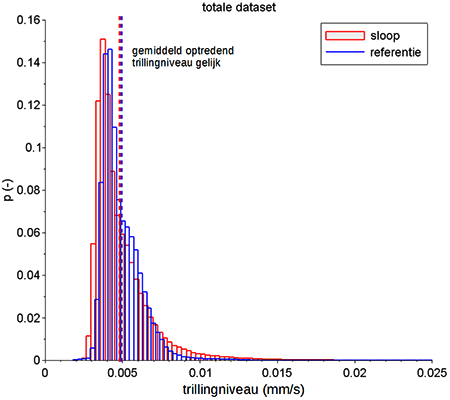 Deze methodiek is toegepast in een onderzoek waarbij het effect van sloopwerkzaamheden op de optredende trillingniveaus ter plaatse van laboratoria inzichtelijk gemaakt moest worden. Hiervoor zijn gedurende een periode waarin geen sloopwerkzaamheden plaatsvonden de optredende trillingniveaus gemonitord om de referentiesituatie te bepalen. Vervolgens zijn de optredende trillingniveaus tijdens de sloopwerkzaamheden gemonitord. Uit de vergelijking tussen beide metingen bleek nauwelijks verschil met de referentiesituatie. Er bleek geen statistisch relevant verschil (0,2%) te zijn in de gemiddeld optredende trillingsniveaus.
Deze methodiek is toegepast in een onderzoek waarbij het effect van sloopwerkzaamheden op de optredende trillingniveaus ter plaatse van laboratoria inzichtelijk gemaakt moest worden. Hiervoor zijn gedurende een periode waarin geen sloopwerkzaamheden plaatsvonden de optredende trillingniveaus gemonitord om de referentiesituatie te bepalen. Vervolgens zijn de optredende trillingniveaus tijdens de sloopwerkzaamheden gemonitord. Uit de vergelijking tussen beide metingen bleek nauwelijks verschil met de referentiesituatie. Er bleek geen statistisch relevant verschil (0,2%) te zijn in de gemiddeld optredende trillingsniveaus.
Door het machine learning-algoritme toe te passen op de datasets zijn verschillende clusters in de data geïdentificeerd. Voor zowel de referentiesituatie als de situatie tijdens sloopwerkzaamheden heeft het algoritme twee clusters gevonden. Zo is er een cluster van data dat dagelijks voorkomende verstoringen representeert en er is een datacluster gevonden dat juist de relatief hoge trillingniveaus representeert.
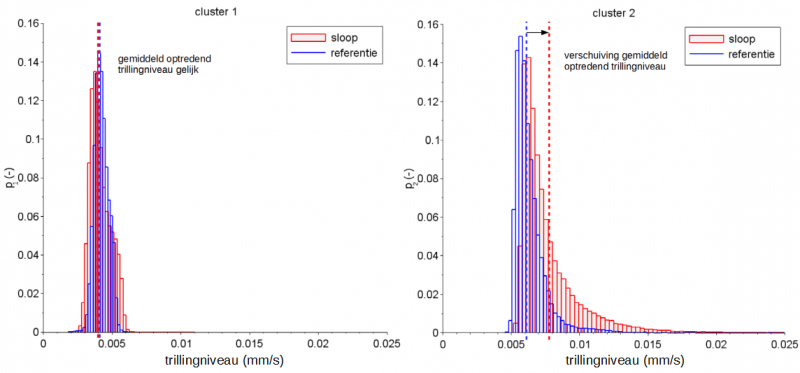 Cluster 1 met de lagere verstoringen is in beide situaties vergelijkbaar. Voor cluster 2 blijkt echter dat voor de sloopwerkzaamheden het clustergemiddelde 21% hoger ligt ten opzichte van de referentie. De mediaan verschuift in mindere mate, waardoor de scheefheid van de distributie toeneemt. De vormverandering van de distributie van cluster 2 is direct te relateren aan de sloopwerkzaamheden, bijvoorbeeld de toename van zwaar vrachtverkeer en gebruik zwaar sloopmaterieel.
Cluster 1 met de lagere verstoringen is in beide situaties vergelijkbaar. Voor cluster 2 blijkt echter dat voor de sloopwerkzaamheden het clustergemiddelde 21% hoger ligt ten opzichte van de referentie. De mediaan verschuift in mindere mate, waardoor de scheefheid van de distributie toeneemt. De vormverandering van de distributie van cluster 2 is direct te relateren aan de sloopwerkzaamheden, bijvoorbeeld de toename van zwaar vrachtverkeer en gebruik zwaar sloopmaterieel.
Deze methodiek is breed toepasbaar. De methodiek kan bijvoorbeeld ook gebruikt worden om op basis van frequentie-karakteristieken verborgen verbanden uit datasets te halen en te gebruiken om geluid- of trillingbronnen te identificeren in tijdreeksen. Zo zijn er tal van praktijksituaties waar het gewenst is om van grote datasets de onderliggende structuur inzichtelijk te maken.
Machine learning-algoritmes bieden grote toegevoegde waarde in het vinden van verborgen structuren en verbanden in grote datasets.
Vooral in situaties waarbij hinder wordt ondervonden van geluid of trillingen, maar de aard en het aantal bronnen onbekend is, kan een machine learning-algoritme inzicht geven in de grote hoeveelheid gegevens. De interpretatie door de adviseur met expertkennis van de informatie die zo ontsloten wordt leidt tot meer inzichten die het advies verdiepen. Voelt u zich vrij contact op te nemen wanneer u hier meer informatie over wenst.